字节跳动埋点数据流建设与治理实践(3)
Yarn优化
另一方面我们注意到Flink Credit-Based flow control反压机制中,可以用backlog size去判断下游Task的处理负载,我们也就可以将Round Robin的发送方式修改为根据Channel的Backlog size信息,去选择负载更低的下游Channel进行发送。这个Feature上线后,队列的负载变得更加均衡,CPU的使用率也提升了10%。
挑战主要是流量大和业务多导致的。流量大服务规模就大,不仅会导致成本治理的问题,还会带来单机故障多、性能瓶颈等因素引发的稳定性问题。而下游业务多、需求变化频繁,推荐、广告、实时数仓等下游业务对稳定性和实时性都有比较高的要求。
在流量大、业务多这样的背景下,如何保障埋点数据流稳定性的同时降低成本、提高效率,是埋点数据流稳定性治理和成本治理面对的挑战。
为了优化这些问题,BMQ这款字节跳动自研的存储计算分离的MQ应运而生。BMQ的数据存储使用了HDFS分布式存储,每个Partition的数据切分为多个segment,每个segment对应一个HDFS文件,Proxy和Broker都是无状态的,因此可以支持快速的扩缩容,并且由于没有数据拷贝所以扩缩容操作也不会影响读写性能。
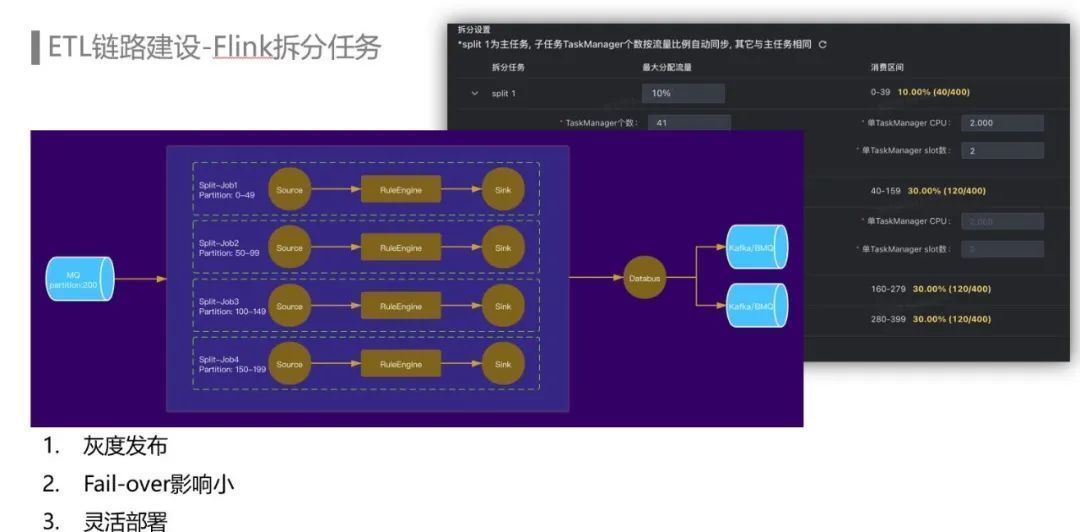
ETL任务规模体量较大,在多个机房部署了超过1000个Flink任务和超过1000个MQ Topic,使用了超过50万Core CPU资源,单个任务最大超过12万Core CPU,单个MQ Topic最大达到个partition。
埋点数据流ETL链路发展到现在主要经历了三个阶段。
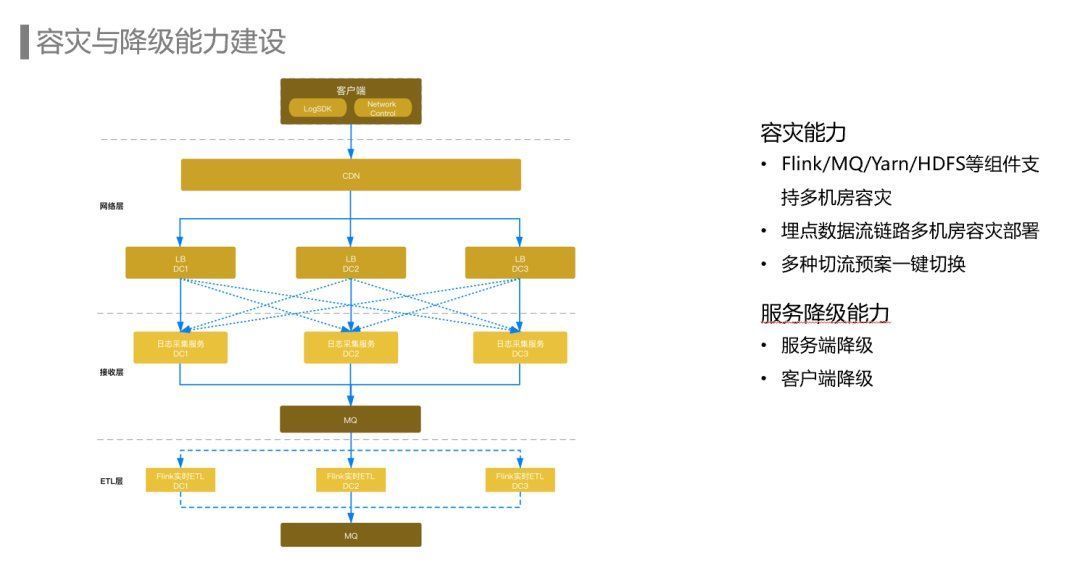
容灾与降级能力建设
Yarn层面的优化,第一个是队列资源层面,我们使用独立的Label队列可以避免高峰期被其他低优任务影响。
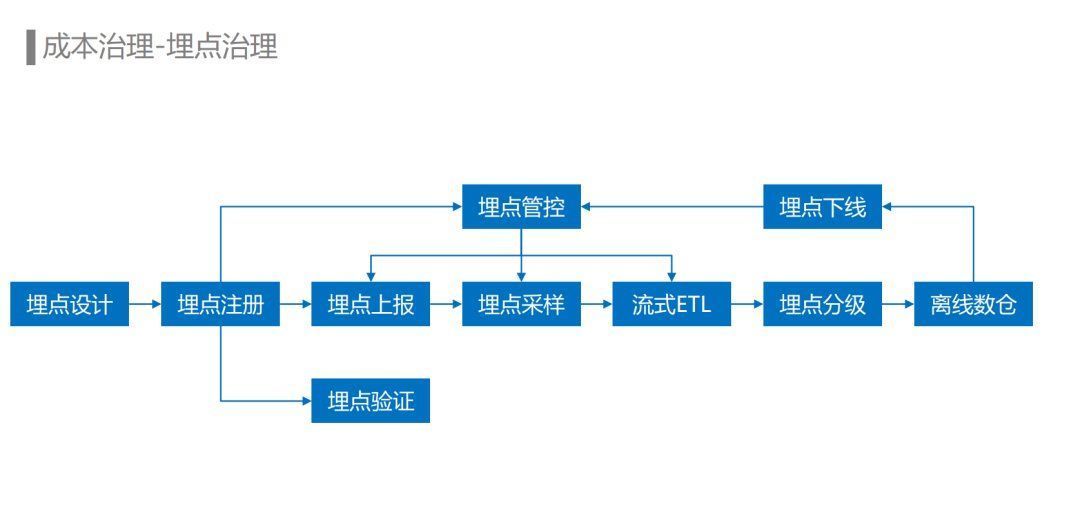
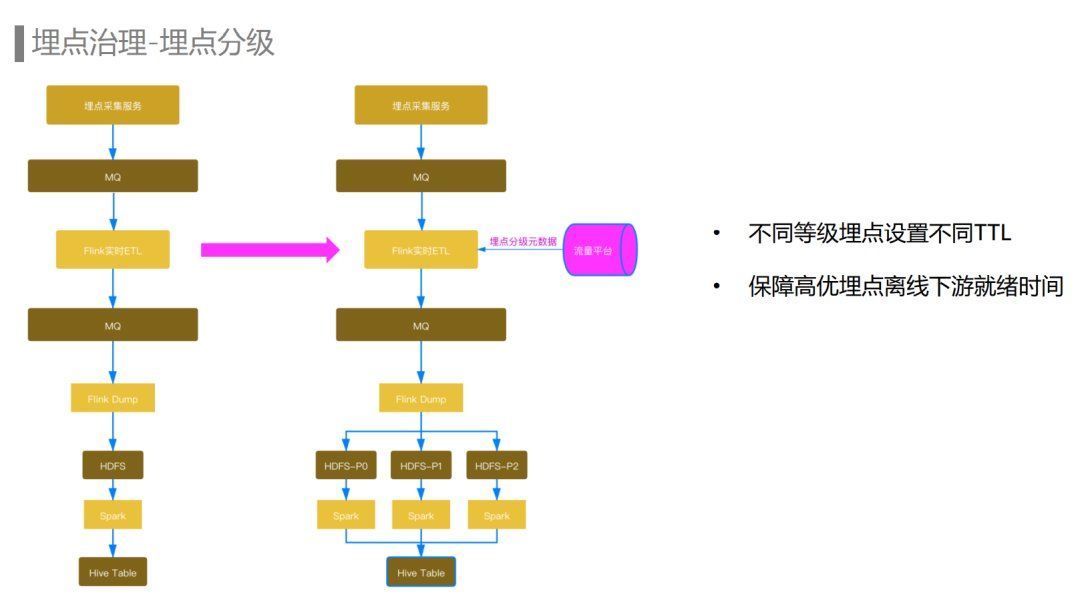
成本治理-埋点治理
字节跳动埋点数据流的规模比较大,体现在以下几个方面:
单机问题优化
上文我们了解了埋点数据流的业务场景和面对的挑战,接下来会介绍埋点数据流在ETL链路建设和容灾与降级能力上的一些实践。
除了规则引擎的迭代,我们在平台侧的测试发布和监控方面也做了很多建设。测试发布环节支持了规则的线下测试,线上调试,以及灰度发布的功能。监控环节支持了字段、规则、任务等不同粒度的异常监控,如规则的流量波动报警、任务的资源报警等。
客户端埋点
在埋点治理方面,通过对流量平台的建设,提供了从埋点设计、埋点注册、埋点验证、埋点上报、埋点采样、流式ETL处理,再到埋点下线的埋点全生命周期的管理能力。
当OutputMessage输出到Slink后,Slink根据其中的路由信息将数据发送到SlinkManager管理的不同的Client中,然后由对应的Client发送到下游的MQ中。
规则引擎
ETL规则动态更新
容灾降级
因此我们提供了数据分流服务,实现上是我们使用一个Flink任务去消费上游埋点Topic,通过在任务中配置分流规则的方式,将各个业务关注的埋点分流到下游的小Topic中提供给各业务消费,减少不必要的资源开销,同时也降低了MQ集群出带宽。
为了提升下流推荐系统的处理效率,我们在数据流配置ETL规则对推荐关注的埋点进行过滤,并对字段进行删减、映射、标准化等清洗处理,将埋点打上不同的动作类型标识,处理之后的埋点内部一般称为UserAction。UserAction与服务端展现、Feature等数据会在推荐Joiner任务的分钟级窗口中进行拼接处理,产出instance训练样本。
数据分流
由于Python脚本语言本身的灵活性,基于Python实现动态加载规则比较简单。通过Compile函数可以将一段代码片段编译成字节代码,再通过eval函数进行调用就可以实现。但Python规则引擎存在性能较弱、规则缺乏管理等问题。
在埋点数据流这种大流量场景下使用Kafka,会经常遇到Broker或者磁盘负载不均、磁盘坏掉等情况导致的稳定性问题,以及Kafka扩容、Broker替换等运维操作也会影响集群任务正常的读写性能,除此之外Kafka还有controller性能瓶颈、多机房容灾部署成本高等缺点。
对于已经上报的埋点,通过埋点血缘统计出已经没有在使用的埋点,自动通知埋点负责人在流量平台进行自助下线。埋点下线流程完成后会通过服务端动态下发配置到埋点SDK以及埋点数据流ETL任务中,确保未注册的埋点在上报或者ETL环节被丢弃掉。还支持通过埋点黑名单的方式对一些异常的埋点进行动态的封禁。
文章来源:《桥梁建设》 网址: http://www.qljszzs.cn/zonghexinwen/2022/0822/1083.html
上一篇:浙江宁波:桥梁架设施工忙
下一篇:以作风建设和能力建设的实际成效推进工会组织