字节跳动埋点数据流建设与治理实践(4)
埋点分级
数据流的时效性
埋点数据流建设实践
埋点数据流治理实践
拆分任务的应用使得数据流除了规则粒度的灰度发布能力之外,还具备了Job粒度的灰度发布能力,升级扩容的时候不会发生断流,上线的风险更可控。同时由于拆分任务的各子任务是独立的,因此单个子任务出现反压、Failover对下游的影响更小。另一个优点是,单个子任务的资源使用量更小,资源可以同时在多个队列进行灵活的部署。
发展历程
用户在使用 App 、小程序、 Web 等各种线上应用时产生的用户行为数据主要通过埋点的形式进行采集上报,按不同的来源可以分为:
说到ETL链路建设,埋点数据流在容灾与降级能力建设方面也进行了一些实践。
介绍完埋点数据流建设的实践,接下来给大家分享的是埋点数据流治理方面的一些实践。埋点数据流治理包含多个治理领域,比如稳定性、成本、埋点质量等,每个治理领域下面又有很多具体的治理项目。
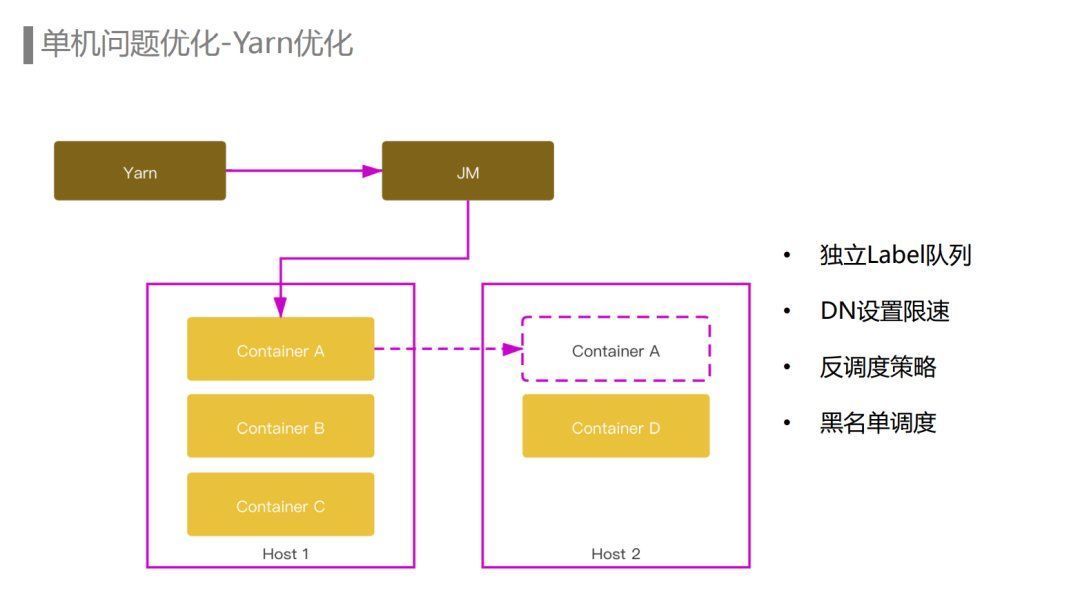
首先是Flink层面的优化,在埋点数据流ETL场景中,为了减少不必要的网络传输,我们的Partitioner主要采用的是Rescale Partitioner,而Rescale Partitioner会使用Round-Robin的方式发送数据到下游Channel中。由于单机问题可能导致下游个别Task反压或者处理延迟从而引起反压,而实际上在这个场景里面,数据从上游task发送到任何一个下游的Task都是可以的,合理的策略应该是根据下游的Task的处理能力去发送数据,而不是用Round-Robin方式。
Databus应用
埋点管控
另外我们会针对一些频繁出问题的节点把它们加入调度的黑名单,在调度的时候避免将container调度到这些节点。
Kafka迁移BMQ
MQ优化
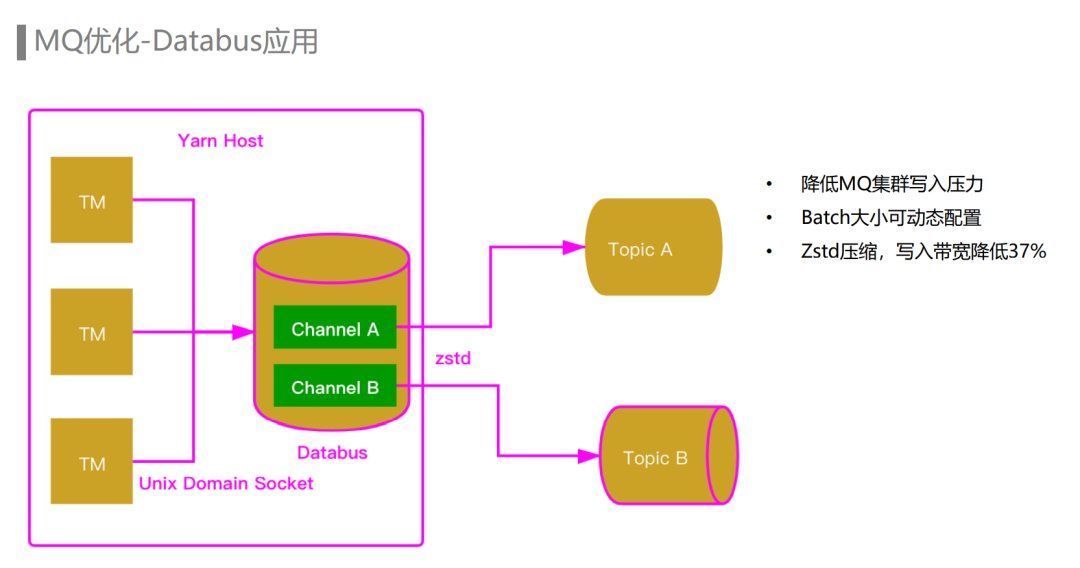
在流量迅速增长的阶段,埋点数据流Flink任务一开始是通过Kafka Connecter直接写入Kafka。但由于任务处理的流量非常大,Flink任务中Sink并发比较多,导致批量发送的效率不高,Kafka集群写入的请求量非常大。并且由于每个Sink一个或多个Client,Client与Kafka之间建立的连接数也非常多。而Kafka由于Controller的性能瓶颈无法继续扩容,所以为了缓解Kafka集群的压力,埋点数据流的Flink任务引入了Databus组件。Databus是一种以Agent方式部署在各个节点上的MQ写入组件。Databus Agent可以配置多个Channel,每个Channel对应一个Kafka的Topic。Flink Job每个Task Manager里面的Sink会通过Unix Domain Socket的方式将数据发送到节点上Databus Agent的Channel里面,再由Databus将数据批量地发送到对应的Kafka Topic。由于一个节点上会有多个Task Manager,每个Task Manager都会先把数据发送到节点上的Databus Agent,Databus Agent中的每个Channel实际上聚合了节点上所有Task Manager写往同一个Topic数据,因此批量发送的效率非常高,极大地降低了Kafka集群的写入请求量,并且与Kafka集群之间建立的连接数也更少,通过Agent也能方便地设置数据压缩算法,由于批量发送的原因压缩效率比较高。在我们开启了Zstd压缩后,Kafka集群的写入带宽降低了37%,极大地缓解了Kafka集群的压力。
受益于HDFS已经建设得比较完善的多机房容灾能力,BMQ多机房容灾部署就变的非常简单,数据同时写入所有容灾机房后再返回成功即可保障多机房容灾。数据消费是在每个机房读取本地的HDFS进行消费,减少了跨机房带宽。除此之外,由于基于多机房HDFS存储比Kafka集群多机房部署所需的副本更少,所以最终实现了单GB流量成本对比Kafka下降了50%的资源收益。

Web端埋点
业务场景
未来规划
但规则引擎本身的迭代、流量增长导致的资源扩容等场景,还是需要升级重启Flink任务,导致下游断流。
接入的业务数量很多,包括抖音、今日头条、西瓜视频、番茄小说在内的多个App和服务,都接入了埋点数据流。
文章来源:《桥梁建设》 网址: http://www.qljszzs.cn/zonghexinwen/2022/0822/1083.html
上一篇:浙江宁波:桥梁架设施工忙
下一篇:以作风建设和能力建设的实际成效推进工会组织