字节跳动埋点数据流建设与治理实践(2)
UserAction ETL
Yarn单机问题导致Flink 任务Failover、反压、消费能力下降是比较常见的case。
除了重启断流外,大任务还可能在重启时遇到启动慢、队列资源不足或者资源碎片导致起不来等情况。
反调度策略中,Yarn会定期检查不满足原有约束的Container,并在这些Container所在节点上筛选出需要重新调度的Container返还给Flink Job Manager,然后Flink会重新调度这些Container,重新调度会按照原有的约束条件尝试申请等量的可用资源,申请成功后再进行迁移。
埋点数据流遇到挑战
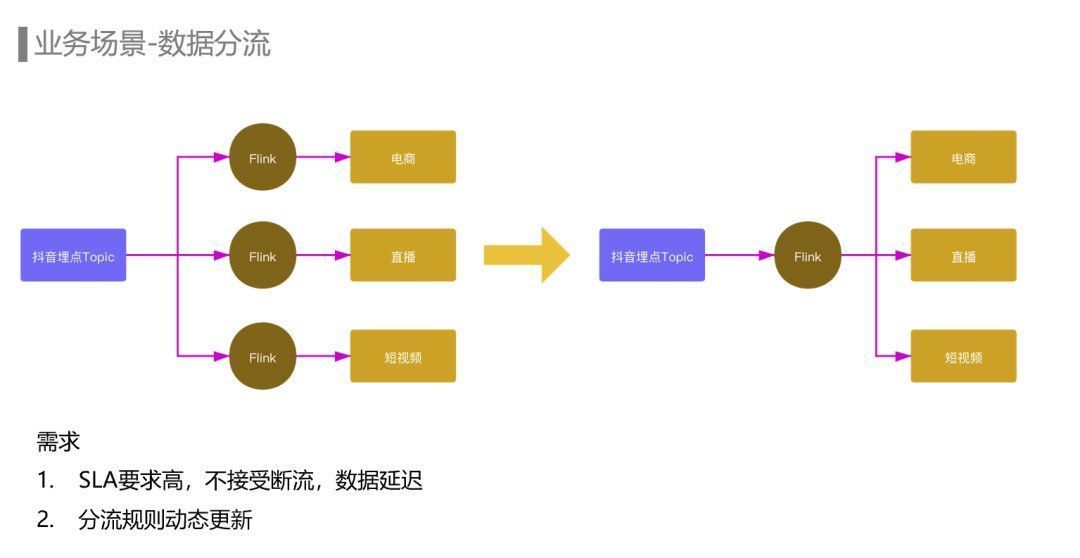
抖音的埋点Topic晚高峰超过一亿每秒,而下游电商、直播、短视频等不同业务关注的埋点都只是其中一部分。如果每个业务都分别使用一个Flink任务去消费抖音的全量埋点去过滤出自己关注的埋点,会消耗大量的计算资源,同时也会造成MQ集群带宽扇出非常严重,影响MQ集群的稳定性。
针对这些痛点我们上线了Flink拆分任务,本质上是将一个大任务拆分为一组子任务,每个子任务按比例去消费上游Topic的部分Partition,按相同的逻辑处理后再分别写出到下游Topic。
ETL链路建设
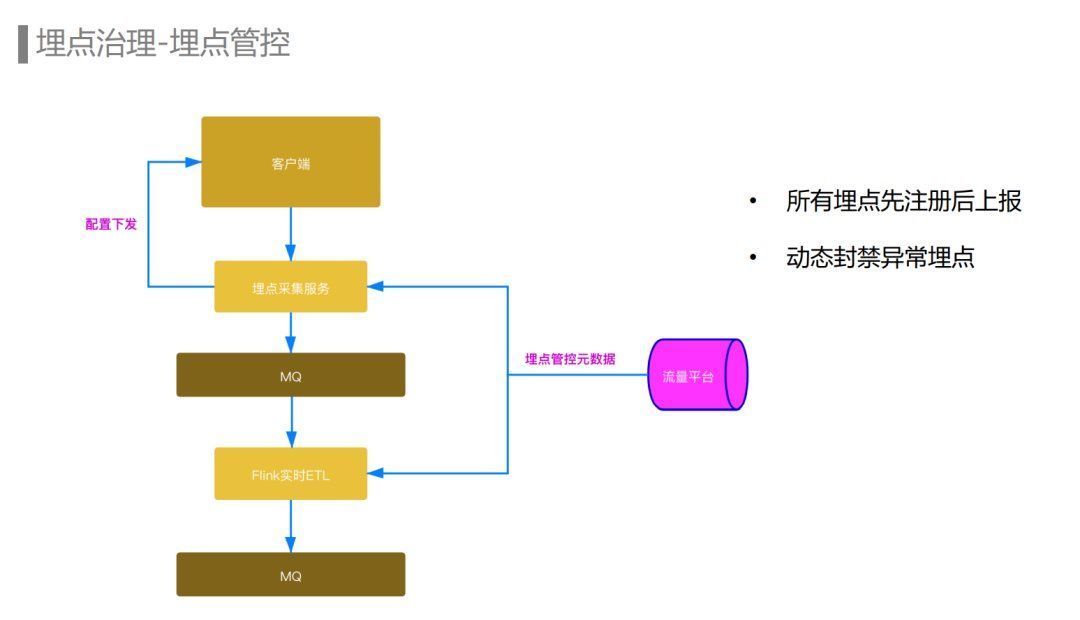
目前字节跳动所有的产品都开启了埋点管控。所有的埋点都需要在我们的流量平台上注册埋点元数据之后才能上报。而我们的埋点数据流ETL也只会处理已经注册的埋点,这是从埋点接入流程上进行的管控。
规则引擎的应用解决了埋点数据流ETL链路如何快速响应业务需求的问题,实现了ETL规则的动态更新,从而修改ETL规则不需要修改代码和重启任务。
如果产出UserAction数据的ETL链路出现比较大的延迟,就不能在拼接窗口内及时地完成训练样本的拼接,可能会导致用户体验的下降,因此对于推荐来说,数据流的时效性是比较强的需求。而推荐模型的迭代和产品埋点的变动都可能导致UserAction ETL规则的变动,如果我们把这个ETL规则硬编码在代码中,每次修改都需要升级代码并重启相关的Flink ETL任务,这样会影响数据流的稳定性和数据的时效性,因此这个场景的另一个需求是ETL规则的动态更新。
另一个场景是容灾降级。数据流容灾首先考虑的是防止单个机房级别的故障导致埋点数据流完全不可用,因此埋点数据流需要支持多机房的容灾部署。其次当出现机房级别的故障时,需要将故障机房的流量快速调度到可用机房实现服务的容灾恢复,因此需要埋点数据流具备机房间快速切流的能力。
Flink BacklogRescale
基于规则引擎的Flink ETL
举个例子:上游Topic有200个Partition,我们在一站式开发平台上去配置Flink拆分任务时只需要指定每个子任务的流量比例,每个子任务就能自动计算出它需要消费的topic partition区间,其余参数也支持按流量比例自动调整。
埋点数据流主要处理的数据是埋点,埋点也叫Event Tracking,是数据和业务之间的桥梁,也是数据分析、推荐、运营的基石。

流量很大,当前字节跳动埋点数据流峰值流量超过1亿每秒,每天处理超过万亿量级埋点,PB级数据存储增量。
在介绍业务场景时,提到我们一个主要的需求是ETL规则的动态更新,那么我们来看一下埋点数据流Flink ETL 任务是如何基于规则引擎支持动态更新的,如何在不重启任务的情况下,实时的更新上下游的Schema信息、规则的处理逻辑以及修改路由拓扑。
在推荐场景中,由于埋点种类多、流量巨大,而推荐只关注其中部分埋点,因此需要通过UserAction ETL对埋点流进行处理,对这个场景来说有两个需求点:
迁移到Java Flink后,在流量平台上统一管理运维ETL规则以及schema、数据集等元数据,用户在流量平台编辑相应的ETL规则,从前端发送到后端,经过一系列的校验最终保存为逻辑规则。引擎会将这个逻辑规则编译为实际执行的物理规则,基于Groovy的引擎通过GroovyClassLoader动态加载规则和对应的UDF。虽然Groovy引擎性能比Python引擎提升了多倍,但Groovy本身也存在额外的性能开销,因此我们又借助Janino可以动态高效地编译Java代码直接执行的能力,将Groovy替换成了Janino,同时也将处理Protobuf数据时使用的DynamicMessage替换成了GeneratedMessage,整体性能提升了10倍。
而数据流降级主要考虑的是埋点数据流容量不足以承载全部流量的场景,比如春晚活动、电商大促这类有较大突发流量的场景。为了保障链路的稳定性和可用性,需要服务具备主动或者被动的降级能力。
文章来源:《桥梁建设》 网址: http://www.qljszzs.cn/zonghexinwen/2022/0822/1083.html
上一篇:浙江宁波:桥梁架设施工忙
下一篇:以作风建设和能力建设的实际成效推进工会组织